'Webscraping Google Search Results Using Google API - Returns same result over and over again
My problem
Hi everyone
I am attempting to develop my very first web scraper using the Google API and Beautiful Soup in Python.
The aim is for the scraper to ask the user for an input, do a normal Google search and return a number of results in a nicely formatted way.
My current code succeeds in retrieving the data, but it only returns 1 result. When I try to do a loop on the results, in just keeps giving me the same result over and over again.
What I actually want is for the script to iterate over the different results on e.g. first page of Google search results and return all of these results. I am quite new to coding and I am guessing it's somewhere in my loop that I am making the mistake, but I guess it could also be something in the API?
I would very much appreciate some help here. Also the formatting of the code might be horrible, feel free to critique it so I can better at writing nice code :D
current code is
import sys
import urllib.request
import urllib.parse
import re
from urllib.request import urlopen as ureqs
from bs4 import BeautifulSoup as soup
from googleapiclient.discovery import build
# Google Personal Search Engine information
my_api_key = <key>
my_cse_id = <id>
# Google Search
def google_search(search_term, api_key, cse_id, **kwargs):
service = build('customsearch', 'v1', developerKey=api_key)
res = service.cse().list(q=search_term, cx=cse_id, **kwargs).execute()
return res
# Setting up so that user can input query
query = input("enter the query\n")
# Getting into printing the results
results = google_search(query, my_api_key, my_cse_id)
print("\n*********Google Search Results*********\n")
for i in results:
print("Title == " +results['items'][0]['title'])
print("Link ==" +results['items'][0]['link'])
snippet = results['items'][0]['snippet'].replace('\n', "")
html_snippet = results['items'][0]['htmlSnippet'].replace('\n', "")
html_snippet = html_snippet.replace("<b>", "")
html_snippet = html_snippet.replace("</b>", "")
html_snippet = html_snippet.replace("<br>", "")
html_snippet = html_snippet.replace(" …", ".")
print("Description == " + snippet+html_snippet)
Solution 1:[1]
Your code is constantly iterating over the first element. This is because you are not using a i - loop local variable.
The for statement in Python can iterate over the elements of any sequence in the order they appear in the sequence (list or string). If you need to iterate over a sequence of numbers, the range() built-in function comes in handy.
I used the second option with the range() function, where the variable i was used as the iteration number, which corresponds to the indices in the resulting array of values ??and allows each iteration to output a new value at the index. The len() built-in function is used to count the number of elements in a sequence and return the number to the range() function, thus passing in how many times the loop should be iterated.
Below is a modified snippet of your code. I also added f-strings which is a more pythonic way of concatenating strings that looks cleaner:
# your code
for i in range(len(results)):
print(f"Title == {results['items'][i]['title']}")
print(f"Link == {results['items'][i]['link']}")
snippet = results['items'][i]['snippet'].replace('\n', "")
html_snippet = results['items'][i]['htmlSnippet'].replace('\n', "")
html_snippet = html_snippet.replace("<b>", "")
html_snippet = html_snippet.replace("</b>", "")
html_snippet = html_snippet.replace("<br>", "")
html_snippet = html_snippet.replace(" …", ".")
print(f"Description == {snippet}{html_snippet}", end="\n\n")
A solution that does the same but using only the Beautiful Soup library:
# variant using only the Beautiful Soup library
for result in soup.select(".tF2Cxc"):
title = f'Title: {result.select_one("h3").text}'
link = f'Link: {result.select_one("a")["href"]}'
description = f'Description: {result.select_one(".VwiC3b").text}'
print(title, link, description, sep="\n", end="\n\n")
I decided to present an option using only the Beautiful Soup library, since your code uses a lot of libraries that you can do without. I also noticed that you manually remove the tags, although this can be done more easily by selecting the text of the .VwiC3b selector. This will ignore the inner tags and take their contents.
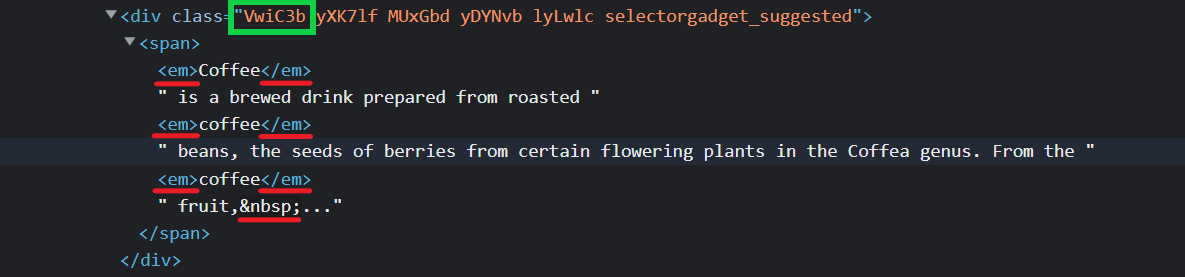
Also, make sure you're using request headers user-agent to act as a "real" user visit. Because default requests user-agent is python-requests and websites understand that it's most likely a script that sends a request. Check what's your user-agent.
Code and full example in online IDE:
import sys
import urllib.request
import urllib.parse
import re
from urllib.request import urlopen as ureqs
from bs4 import BeautifulSoup as soup
from googleapiclient.discovery import build
# Google Personal Search Engine information
my_api_key = <key>
my_cse_id = <id>
# Google Search
def google_search(search_term, api_key, cse_id, **kwargs):
service = build('customsearch', 'v1', developerKey=api_key)
res = service.cse().list(q=search_term, cx=cse_id, **kwargs).execute()
return res
# Setting up so that user can input query
query = input("Enter the query:\n")
# Getting into printing the results
results = google_search(query, my_api_key, my_cse_id)
print("\n*********Google Search Results*********\n")
for i in range(len(results)):
print(f"Title == {results['items'][i]['title']}")
print(f"Link == {results['items'][i]['link']}")
snippet = results['items'][i]['snippet'].replace('\n', "")
html_snippet = results['items'][i]['htmlSnippet'].replace('\n', "")
html_snippet = html_snippet.replace("<b>", "")
html_snippet = html_snippet.replace("</b>", "")
html_snippet = html_snippet.replace("<br>", "")
html_snippet = html_snippet.replace(" …", ".")
print(f"Description == {snippet}{html_snippet}", end="\n\n")
Output:
*********Google Search Results*********
Title == Coffee - Wikipedia
Link == https://en.wikipedia.org/wiki/Coffee
Description == Coffee is a brewed drink prepared from roasted coffee beans, the seeds of berries from certain flowering plants in the Coffea genus. From the coffee fruit, ...Coffee is a brewed drink prepared from roasted coffee beans, the seeds of berries from certain flowering plants in the Coffea genus. From the coffee fruit, ...
Title == Starbucks Coffee Company
Link == https://www.starbucks.com/
Description == More than just great coffee. Explore the menu, sign up for Starbucks® Rewards, manage your gift card and more.More than just great coffee. Explore the menu, sign up for Starbucks® Rewards, manage your gift card and more.
... other results
Using Beautiful Soup:
from bs4 import BeautifulSoup
import requests, lxml
query = input("Enter the query:\n")
# https://docs.python-requests.org/en/master/user/quickstart/#passing-parameters-in-urls
params = {
"q": query,
"hl": "en", # language
"gl": "us" # country of the search, US -> USA
}
# https://docs.python-requests.org/en/master/user/quickstart/#custom-headers
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/100.0.4896.88 Safari/537.36",
}
html = requests.get("https://www.google.com/search", params=params, headers=headers, timeout=30)
soup = BeautifulSoup(html.text, "lxml")
for result in soup.select(".tF2Cxc"):
title = f'Title: {result.select_one("h3").text}'
link = f'Link: {result.select_one("a")["href"]}'
description = f'Description: {result.select_one(".VwiC3b").text}'
print(title, link, description, sep="\n", end="\n\n")
Output:
Title: Coffee - Wikipedia
Link: https://en.wikipedia.org/wiki/Coffee
Description: Coffee is a brewed drink prepared from roasted coffee beans, the seeds of berries from certain flowering plants in the Coffea genus. From the coffee fruit, ...
Title: Starbucks Coffee Company
Link: https://www.starbucks.com/
Description: More than just great coffee. Explore the menu, sign up for Starbucks® Rewards, manage your gift card and more.
... other results
Alternatively, you can use Google Organic Results API from SerpApi. It`s a paid API with the free plan.
The difference is that it will bypass blocks from Google or other search engines, so the end-user doesn't have to figure out how to do it, maintain the parse, and only think about what data to retrieve instead.
Example code to integrate:
from serpapi import GoogleSearch
import os
query = input("Enter the query:\n")
params = {
# https://docs.python.org/3/library/os.html#os.getenv
"api_key": os.getenv("API_KEY"), # your serpapi api key
"engine": "google", # search engine
"q": query # search query
# other parameters
}
search = GoogleSearch(params) # where data extraction happens on the SerpApi backend
results = search.get_dict() # JSON -> Python dict
for result in results["organic_results"]:
print(result["title"], result["link"], result["snippet"], sep="\n", end="\n\n")
Output:
Coffee - Wikipedia
https://en.wikipedia.org/wiki/Coffee
Coffee is a brewed drink prepared from roasted coffee beans, the seeds of berries from certain flowering plants in the Coffea genus. From the coffee fruit, ...
Starbucks Coffee Company
https://www.starbucks.com/
More than just great coffee. Explore the menu, sign up for Starbucks® Rewards, manage your gift card and more.
... other results
Disclaimer, I work for SerpApi.
Solution 2:[2]
You iterate through results, but you never use object i inside the loop. Instead you always display results['items'][0]’s result
Sources
This article follows the attribution requirements of Stack Overflow and is licensed under CC BY-SA 3.0.
Source: Stack Overflow
| Solution | Source |
|---|---|
| Solution 1 | Artur Chukhrai |
| Solution 2 |